
| CV |
Email |
Google Scholar |
|
I am a Member of Technical Staff at OpenAI building physical AGI. I received my Ph.D. from the Robotics Institute at Carnegie Mellon University, where I was advised by Guanya Shi and Changliu Liu. During my Ph.D., I spent two wonderful years interning at NVIDIA GEAR Lab led by Jim Fan and Yuke Zhu. My PhD research was supported by the CMU RI Presidential Fellowship and NVIDIA Graduate Fellowship. Before that, I received my B.S. in Computer Science from Shanghai Jiao Tong University, advised by Weinan Zhang, and spent time at Microsoft Research Asia. Goal: Robots that improve everyone's life. Research Interest: The intersection of robotics, large-scale machine learning, and general-purpose loco-manipulation. Research Question: How can we build a scalable robot learning flywheel that unifies perception, whole-body control, and dexterous manipulation, enabling reliable general-purpose robots in unstructured, real-world environments? Robots: I love working on humanoids and aim to make them capable of doing everything I can do—and more. Email: tairanhe1999 [AT] gmail.com |
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Recent progress in GPU-accelerated, photorealistic simulation has opened a scalable data-generation path for robot learning, where massive physics and visual randomization allow policies to generalize beyond curated environments. Building on these advances, we develop a teacher-student-bootstrap learning framework for vision-based humanoid loco-manipulation, using articulated-object interaction as a representative high-difficulty benchmark. Our approach introduces a staged-reset exploration strategy that stabilizes long-horizon privileged-policy training, and a GRPO-based fine-tuning procedure that mitigates partial observability and improves closed-loop consistency in sim-to-real RL. Trained entirely on simulation data, the resulting policy achieves robust zero-shot performance across diverse door types and outperforms human teleoperators by up to 31.7% in task completion time under the same whole-body control stack. This represents the first humanoid sim-to-real policy capable of diverse articulated loco-manipulation using pure RGB perception.
@article{xue2025openingsimtorealdoorhumanoid,
title={Opening the Sim-to-Real Door for Humanoid Pixel-to-Action Policy Transfer},
author={Haoru Xue and Tairan He and Zi Wang and Qingwei Ben and Wenli Xiao and Zhengyi Luo and Xingye Da and Fernando Castañeda and Guanya Shi and Shankar Sastry and Linxi "Jim" Fan and Yuke Zhu},
year={2025},
eprint={2512.01061},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.01061}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays—with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
@article{he2025viral,
title={VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation},
author={He, Tairan and Wang, Zi and Xue, Haoru and Ben, Qingwei and Luo, Zhengyi and Xiao, Wenli and Yuan, Ye and Da, Xingye and Castañeda, Fernando and Sastry, Shankar and Liu, Changliu and Shi, Guanya and Fan, Linxi and Zhu, Yuke},
journal={arXiv preprint arXiv:2511.15200},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
@article{luo2025sonic,
title={SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control},
author={Luo, Zhengyi and Yuan, Ye and Wang, Tingwu and Li, Chenran and Chen, Sirui and Casta\~neda, Fernando and Cao, Zi-Ang and Li, Jiefeng and Minor, David and Ben, Qingwei and Da, Xingye and Ding, Runyu and Hogg, Cyrus and Song, Lina and Lim, Edy and Jeong, Eugene and He, Tairan and Xue, Haoru and Xiao, Wenli and Wang, Zi and Yuen, Simon and Kautz, Jan and Chang, Yan and Iqbal, Umar and Fan, Linxi and Zhu, Yuke},
journal={arXiv preprint arXiv:2511.07820},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Enabling robust whole-body humanoid-object interaction (HOI) remains challenging due to motion data scarcity and the contact-rich nature. We present HDMI (HumanoiD iMitation for Interaction), a simple and general framework that learns whole-body humanoid-object interaction skills directly from monocular RGB videos. Our pipeline (i) extracts and retargets human and object trajectories from unconstrained videos to build structured motion datasets, (ii) trains a reinforcement learning (RL) policy to co-track robot and object states with three key designs: a unified object representation, a residual action space, and a general interaction reward, and (iii) zero-shot deploys the RL policies on real humanoid robots. Extensive sim-to-real experiments on a Unitree G1 humanoid demonstrate the robustness and generality of our approach: HDMI achieves 67 consecutive door traversals and successfully performs 6 distinct loco-manipulation tasks in the real world and 14 tasks in simulation. Our results establish HDMI as a simple and general framework for acquiring interactive humanoid skills from human videos.
@article{weng2025hdmi,
title={HDMI: Learning Interactive Humanoid Whole-Body Control from Human Videos},
author={Weng, Haoyang and Li, Yitang and Sobanbabu, Nikhil and Wang, Zihan and Luo, Zhengyi and He, Tairan and Ramanan, Deva and Shi, Guanya},
journal={arXiv preprint arXiv:2509.16757},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Humanoid loco-manipulation holds transformative potential for daily service and industrial tasks, yet achieving precise, robust whole-body control with 3D end-effector force interaction remains a major challenge. Prior approaches are often limited to lightweight tasks or quadrupedal/wheeled platforms. To overcome these limitations, we propose FALCON, a dual-agent reinforcement-learning-based framework for robust force-adaptive humanoid loco-manipulation. FALCON decomposes whole-body control into two specialized agents: (1) a lower-body agent ensuring stable locomotion under external force disturbances, and (2) an upper-body agent precisely tracking end-effector positions with implicit adaptive force compensation. These two agents are jointly trained in simulation with a force curriculum that progressively escalates the magnitude of external force exerted on the end effector while respecting torque limits. Experiments demonstrate that, compared to the baselines, FALCON achieves 2x more accurate upper-body joint tracking, while maintaining robust locomotion under force disturbances and achieving faster training convergence. Moreover, FALCON enables policy training without embodiment-specific reward or curriculum tuning. Using the same training setup, we obtain policies that are deployed across multiple humanoids, enabling forceful loco-manipulation tasks such as transporting payloads (0-20N force), cart-pulling (0-100N), and door-opening (0-40N) in the real world.
@article{zhang2025falcon,
title={FALCON: Learning Force-Adaptive Humanoid Loco-Manipulation},
author={Zhang, Yuanhang and Yuan, Yifu and Gurunath, Prajwal and He, Tairan and Omidshafiei, Shayegan and Agha-mohammadi, Ali-akbar and Vazquez-Chanlatte, Marcell and Pedersen, Liam and Shi, Guanya},
journal={arXiv preprint arXiv:2505.06776},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv
Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
@article{luo2025emergent,
title={Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning},
author={Luo, Zhengyi and Tessler, Chen and Lin, Toru and Yuan, Ye and He, Tairan and Xiao, Wenli and Guo, Yunrong and Chechik, Gal and Kitani, Kris and Fan, Linxi and others},
journal={arXiv preprint arXiv:2505.12278},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Training manipulation policies for humanoid robots with diverse data enhance their robustness and generalization across tasks and platforms. However, learning solely from robot demonstrations is labor-intensive, requiring expensive tele-operated data collection which is difficult to scale. This paper investigates a more scalable data source, egocentric human demonstrations, to serve as cross-embodiment training data for robot learning. We mitigate the embodiment gap between humanoids and humans from both the data and modeling perspectives. We collect an egocentric task-oriented dataset (PH2D) that is directly aligned with humanoid manipulation demonstrations. We then train a human-humanoid behavior policy, which we term Human Action Transformer (HAT). The state-action space of HAT is unified for both humans and humanoid robots and can be differentiably retargeted to robot actions. Co-trained with smaller-scale robot data, HAT directly models humanoid robots and humans as different embodiments without additional supervision. We show that human data improves both generalization and robustness of HAT with significantly better data collection efficiency.
@article{qiu2025-humanpolicy,
title={Humanoid Policy \~{} Human Policy},
author={Ri-Zhao Qiu and Shiqi Yang and Xuxin Cheng and Chaitanya Chawla and Jialong Li and Tairan He and Ge Yan and David J. Yoon and Ryan Hoque and Lars Paulsen and Ge Yang and Jian Zhang and Sha Yi and Guanya Shi and Xiaolong Wang},
journal={arXiv preprint arXiv:2503.13441},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Sim-to-real discrepancies hinder learning-based policies from achieving high-precision tasks in the real world. While Domain Randomization (DR) is commonly used to bridge this gap, it often relies on heuristics and can lead to overly conservative policies with degrading performance when not properly tuned. System Identification (Sys-ID) offers a targeted approach, but standard techniques rely on differentiable dynamics and/or direct torque measurement, assumptions that rarely hold for contact-rich legged systems. To this end, we present SPI-Active (Sampling-based Parameter Identification with Active Exploration), a two-stage framework that estimates physical parameters of legged robots to minimize the sim-to-real gap. SPI-Active robustly identifies key physical parameters through massive parallel sampling, minimizing state prediction errors between simulated and real-world trajectories. To further improve the informativeness of collected data, we introduce an active exploration strategy that maximizes the Fisher Information of the collected real-world trajectories via optimizing the input commands of an exploration policy. This targeted exploration leads to accurate identification and better generalization across diverse tasks. Experiments demonstrate that SPI-Active enables precise sim-to-real transfer of learned policies to the real world, outperforming baselines by 42-63% in various locomotion tasks.
@article{sobanbabu2025sampling,
title={Sampling-based system identification with active exploration for legged robot sim2real learning},
author={Sobanbabu, Nikhil and He, Guanqi and He, Tairan and Yang, Yuxiang and Shi, Guanya},
journal={arXiv preprint arXiv:2505.14266},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Can your humanoid walk up and hand you a full cup of beer, without spilling a drop? While humanoids are increasingly featured in flashy demos like dancing, delivering packages, traversing rough terrain, fine-grained control during locomotion remains a significant challenge. In particular, stabilizing a filled end-effector (EE) while walking is far from solved, due to a fundamental mismatch in task dynamics: locomotion demands slow-timescale, robust control, whereas EE stabilization requires rapid, high-precision corrections. To address this, we propose SoFTA, a Slow-Fast Two-Agent framework that decouples upper-body and lower-body control into separate agents operating at different frequencies and with distinct rewards. This temporal and objective separation mitigates policy interference and enables coordinated whole-body behavior. SoFTA executes upper-body actions at 100 Hz for precise EE control and lower-body actions at 50 Hz for robust gait. It reduces EE acceleration by 2-5x relative to baselines and performs much closer to human-level stability, enabling delicate tasks such as carrying nearly full cups, capturing steady video during locomotion, and disturbance rejection with EE stability.
@inproceedings{li2025hold,
title={Hold My Beer: Learning Gentle Humanoid Locomotion and End-Effector Stabilization Control},
author={Li, Yitang and Zhang, Yuanhang and Xiao, Wenli and Pan, Chaoyi and Weng, Haoyang and He, Guanqi and He, Tairan and Shi, Guanya},
booktitle={RSS 2025 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Humanoid robots hold the potential for unparalleled versatility in performing human-like, whole-body skills. However, achieving agile and coordinated whole-body motions remains a significant challenge due to the dynamics mismatch between simulation and the real world. Existing approaches, such as system identification (SysID) and domain randomization (DR) methods, often rely on labor-intensive parameter tuning or result in overly conservative policies that sacrifice agility. In this paper, we present ASAP (Aligning Simulation and Real-World Physics), a two-stage framework designed to tackle the dynamics mismatch and enable agile humanoid whole-body skills. In the first stage, we pre-train motion tracking policies in simulation using retargeted human motion data. In the second stage, we deploy the policies in the real world and collect real-world data to train a delta (residual) action model that compensates for the dynamics mismatch. Then, ASAP fine-tunes pre-trained policies with the delta action model integrated into the simulator to align effectively with real-world dynamics. We evaluate ASAP across three transfer scenarios: IsaacGym to IsaacSim, IsaacGym to Genesis, and IsaacGym to the real-world Unitree G1 humanoid robot. Our approach significantly improves agility and whole-body coordination across various dynamic motions, reducing tracking error compared to SysID, DR, and delta dynamics learning baselines. ASAP enables highly agile motions that were previously difficult to achieve, demonstrating the potential of delta action learning in bridging simulation and real-world dynamics. These results suggest a promising sim-to-real direction for developing more expressive and agile humanoids.
@article{he2024asap,
author = {He, Tairan and Gao, Jiawei and Xiao, Wenli and Zhang, Yuanhang and Wang, Zi and Wang, Jiashun and Luo, Zhengyi and He, Guanqi and Sobanbabu, Nikhil and Pan, Chaoyi and Yi, Zeji and Qu, Guannan and Kitani, Kris and Hodgins, Jessica and Fan, Linxi "Jim" and Zhu, Yuke and Liu, Changliu and Shi, Guanya},
title = {ASAP: Aligning Simulation and Real-World Physics for Learning Agile Humanoid Whole-Body Skills},
booktitle = {arXiv preprint},
year = {2025},
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Humanoid whole-body control requires adapting to diverse tasks such as navigation, loco-manipulation, and tabletop manipulation, each demanding a different mode of control. For example, navigation relies on root velocity tracking, while tabletop manipulation prioritizes upper-body joint angle tracking. Existing approaches typically train individual policies tailored to a specific command space, limiting their transferability across modes. We present the key insight that full-body kinematic motion imitation can serve as a common abstraction for all these tasks and provide general-purpose motor skills for learning multiple modes of whole-body control. Building on this, we propose HOVER (Humanoid Versatile Controller), a multi-mode policy distillation framework that consolidates diverse control modes into a unified policy. HOVER enables seamless transitions between control modes while preserving the distinct advantages of each, offering a robust and scalable solution for humanoid control across a wide range of modes. By eliminating the need for policy retraining for each control mode, our approach improves efficiency and flexibility for future humanoid applications.
@article{he2024hover,
title={HOVER: Versatile Neural Whole-Body Controller for Humanoid Robots},
author={He, Tairan and Xiao, Wenli and Lin, Toru and Luo, Zhengyi and Xu, Zhenjia and Jiang, Zhenyu and Kautz, Jan and Liu, Changliu and Shi, Guanya and Wang, Xiaolong and Fan, Linxi and Zhu, Yuke},
journal={arXiv preprint arXiv:2410.21229},
year={2024}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Real-world legged locomotion systems often need to reconcile agility and safety for different scenarios. Moreover, the underlying dynamics are often unknown and time-variant (e.g., payload, friction). In this paper, we introduce BAS (Bridging Adaptivity and Safety), which builds upon the pipeline of prior work Agile But Safe (ABS)(He et al.) and is designed to provide adaptive safety even in dynamic environments with uncertainties. BAS involves an agile policy to avoid obstacles rapidly and a recovery policy to prevent collisions, a physical parameter estimator that is concurrently trained with agile policy, and a learned control-theoretic RA (reach-avoid) value network that governs the policy switch. Also, the agile policy and RA network are both conditioned on physical parameters to make them adaptive. To mitigate the distribution shift issue, we further introduce an on-policy fine-tuning phase for the estimator to enhance its robustness and accuracy. The simulation results show that BAS achieves 50% better safety than baselines in dynamic environments while maintaining a higher speed on average. In real-world experiments, BAS shows its capability in complex environments with unknown physics (e.g., slippery floors with unknown frictions, unknown payloads up to 8kg), while baselines lack adaptivity, leading to collisions or. degraded agility. As a result, BAS achieves a 19.8% increase in speed and gets a 2.36 times lower collision rate than ABS in the real world.
@article{zhong2025bridging,
title={Bridging Adaptivity and Safety: Learning Agile Collision-Free Locomotion Across Varied Physics},
author={Zhong, Yichao and Zhang, Chong and He, Tairan and Shi, Guanya},
journal={arXiv preprint arXiv:2501.04276},
year={2025}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video |
media (ieee spectrum)
We present OmniH2O (Omni Human-to-Humanoid), a learning-based system for whole-body humanoid teleoperation and autonomy. Using kinematic pose as a universal control interface, OmniH2O enables various ways for a human to control a full-sized humanoid with dexterous hands, including using real-time teleoperation through VR headset, verbal instruction, and RGB camera. OmniH2O also enables full autonomy by learning from teleoperated demonstrations or integrating with frontier models such as GPT-4. OmniH2O demonstrates versatility and dexterity in various real-world whole-body tasks through teleoperation or autonomy, such as playing multiple sports, moving and manipulating objects, and interacting with humans. We develop an RL-based sim-to-real pipeline, which involves large-scale retargeting and augmentation of human motion datasets, learning a real-world deployable policy with sparse sensor input by imitating a privileged teacher policy, and reward designs to enhance robustness and stability. We release the first humanoid whole-body control dataset, OmniH2O-6, containing six everyday tasks, and demonstrate humanoid whole-body skill learning from teleoperated datasets.
@article{he2024omnih2o,
title={OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning},
author={He, Tairan and Luo, Zhengyi and He, Xialin and Xiao, Wenli and Zhang, Chong and Zhang, Weinan and Kitani, Kris and Liu, Changliu and Shi, Guanya},
journal={arXiv preprint arXiv:2406.08858},
year={2024}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
teaser video |
introduction video |
media (ieee spectrum) |
code
Humanoid activities involving sequential contacts are crucial for complex robotic interactions and operations in the real world and are traditionally solved by model-based motion planning, which is time-consuming and often relies on simplified dynamics models. Although model-free reinforcement learning (RL) has become a powerful tool for versatile and robust whole-body humanoid control, it still requires tedious task-specific tuning and state machine design and suffers from long-horizon exploration issues in tasks involving contact sequences. In this work, we propose WoCoCo (Whole-Body Control with Sequential Contacts), a unified framework to learn whole-body humanoid control with sequential contacts by naturally decomposing the tasks into separate contact stages. Such decomposition facilitates simple and general policy learning pipelines through task-agnostic reward and sim-to-real designs, requiring only one or two task-related terms to be specified for each task. We demonstrated that end-to-end RL-based controllers trained with WoCoCo enable four challenging whole-body humanoid tasks involving diverse contact sequences in the real world without any motion priors: 1) versatile parkour jumping, 2) box loco-manipulation, 3) dynamic clap-and-tap dancing, and 4) cliffside climbing. We further show that WoCoCo is a general framework beyond humanoid by applying it in 22-DoF dinosaur robot loco-manipulation tasks.
@article{zhang2024wococo,
title={WoCoCo: Learning Whole-Body Humanoid Control with Sequential Contacts},
author={Zhang, Chong and Xiao, Wenli and He, Tairan and Shi, Guanya},
journal={arXiv e-prints},
pages={arXiv--2406},
year={2024}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video |
media (ieee spectrum)
We present Human to Humanoid (H2O), a reinforcement learning (RL) based framework that enables real-time whole-body teleoperation of a full-sized humanoid robot with only an RGB camera. To create a large-scale retargeted motion dataset of human movements for humanoid robots, we propose a scalable ''sim-to-data" process to filter and pick feasible motions using a privileged motion imitator. Afterwards, we train a robust real-time humanoid motion imitator in simulation using these refined motions and transfer it to the real humanoid robot in a zero-shot manner. We successfully achieve teleoperation of dynamic whole-body motions in real-world scenarios, including walking, back jumping, kicking, turning, waving, pushing, boxing, etc. To the best of our knowledge, this is the first demonstration to achieve learning-based real-time whole-body humanoid teleoperation.
@article{he2024learning,
title={Learning human-to-humanoid real-time whole-body teleoperation},
author={He, Tairan and Luo, Zhengyi and Xiao, Wenli and Zhang, Chong and Kitani, Kris and Liu, Changliu and Shi, Guanya},
journal={arXiv preprint arXiv:2403.04436},
year={2024}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
real-world demo |
video story |
media (ieee spectrum)
Legged robots navigating cluttered environments must be jointly agile for efficient task execution and safe to avoid collisions with obstacles or humans. Existing studies either develop conservative controllers (< 1.0 m/s) to ensure safety, or focus on agility without considering potentially fatal collisions. This paper introduces Agile But Safe (ABS), a learning-based control framework that enables agile and collision-free locomotion for quadrupedal robots. ABS involves an agile policy to execute agile motor skills amidst obstacles and a recovery policy to prevent failures, collaboratively achieving high-speed and collision-free navigation. The policy switch in ABS is governed by a learned control-theoretic reach-avoid value network, which also guides the recovery policy as an objective function, thereby safeguarding the robot in a closed loop. The training process involves the learning of the agile policy, the reach-avoid value network, the recovery policy, and an exteroception representation network, all in simulation. These trained modules can be directly deployed in the real world with onboard sensing and computation, leading to high-speed and collision-free navigation in confined indoor and outdoor spaces with both static and dynamic obstacles.
@article{he2024agile,
title={Agile but safe: Learning collision-free high-speed legged locomotion},
author={He, Tairan and Zhang, Chong and Xiao, Wenli and He, Guanqi and Liu, Changliu and Shi, Guanya},
journal={arXiv preprint arXiv:2401.17583},
year={2024}
}
|
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code |
video
A critical goal of autonomy and artificial intelligence is enabling autonomous robots to rapidly adapt in dynamic and uncertain environments. Classic adaptive control and safe control provide stability and safety guarantees but are limited to specific system classes. In contrast, policy adaptation based on reinforcement learning (RL) offers versatility and generalizability but presents safety and robustness challenges. We propose SafeDPA, a novel RL and control framework that simultaneously tackles the problems of policy adaptation and safe reinforcement learning. SafeDPA jointly learns adaptive policy and dynamics models in simulation, predicts environment configurations, and fine-tunes dynamics models with few-shot real-world data. A safety filter based on the Control Barrier Function (CBF) on top of the RL policy is introduced to ensure safety during real-world deployment. We provide theoretical safety guarantees of SafeDPA and show the robustness of SafeDPA against learning errors and extra perturbations. Comprehensive experiments on (1) classic control problems (Inverted Pendulum), (2) simulation benchmarks (Safety Gym), and (3) a real-world agile robotics platform (RC Car) demonstrate great superiority of SafeDPA in both safety and task performance, over state-of-the-art baselines. Particularly, SafeDPA demonstrates notable generalizability, achieving a 300% increase in safety rate compared to the baselines, under unseen disturbances in real-world experiments.
@article{xiao2023safe,
title={Safe Deep Policy Adaptation},
author={Xiao, Wenli and He, Tairan and Dolan, John and Shi, Guanya},
journal={arXiv preprint arXiv:2310.08602},
year={2023}
}
|
|
|
pdf |
abstract |
bibtex |
arXiv
An attached arm can significantly increase the applicability of legged robots to several mobile manipulation tasks that are not possible for the wheeled or tracked counterparts. The standard control pipeline for such legged manipulators is to decouple the controller into that of manipulation and locomotion. However, this is ineffective and requires immense engineering to support coordination between the arm and legs, error can propagate across modules causing non-smooth unnatural motions. It is also biological implausible where there is evidence for strong motor synergies across limbs. In this work, we propose to learn a unified policy for whole-body control of a legged manipulator using reinforcement learning. We propose Regularized Online Adaptation to bridge the Sim2Real gap for high-DoF control, and Advantage Mixing exploiting the causal dependency in the action space to overcome local minima during training the whole-body system. We also present a simple design for a low-cost legged manipulator, and find that our unified policy can demonstrate dynamic and agile behaviors across several task setups.
@article{chen2023progressive,
title={Progressive Adaptive Chance-Constrained Safeguards for Reinforcement Learning},
author={Chen, Zhaorun and Chen, Binhao and He, Tairan and Gong, Liang and Liu, Chengliang},
journal={arXiv preprint arXiv:2310.03379},
year={2023}
}
|
|

|
pdf |
abstract |
bibtex |
arXiv
Despite the tremendous success of Reinforcement Learning (RL) algorithms in simulation environments, applying RL to real-world applications still faces many challenges. A major concern is safety, in another word, constraint satisfaction. State-wise constraints are one of the most common constraints in real-world applications and one of the most challenging constraints in Safe RL. Enforcing state-wise constraints is necessary and essential to many challenging tasks such as autonomous driving, robot manipulation. This paper provides a comprehensive review of existing approaches that address state-wise constraints in RL. Under the framework of State-wise Constrained Markov Decision Process (SCMDP), we will discuss the connections, differences, and trade-offs of existing approaches in terms of (i) safety guarantee and scalability, (ii) safety and reward performance, and (iii) safety after convergence and during training. We also summarize limitations of current methods and discuss potential future directions.
@inproceedings{ijcai2023p763,
title = {State-wise Safe Reinforcement Learning: A Survey},
author = {Zhao, Weiye and He, Tairan and Chen, Rui and Wei, Tianhao and Liu, Changliu},
booktitle = {Proceedings of the Thirty-Second International Joint Conference on
Artificial Intelligence, {IJCAI-23}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
editor = {Edith Elkind},
pages = {6814--6822},
year = {2023},
month = {8},
note = {Survey Track},
doi = {10.24963/ijcai.2023/763},
url = {https://doi.org/10.24963/ijcai.2023/763},
}
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
Visual imitation learning enables reinforcement learning agents to learn to be- have from expert visual demonstrations such as videos or image sequences, with- out explicit, well-defined rewards. Previous research either adopted supervised learning techniques or induce simple and coarse scalar rewards from pixels, ne- glecting the dense information contained in the image demonstrations. In this work, we propose to measure the expertise of various local regions of image sam- ples, or called patches, and recover multi-dimensional patch rewards accordingly. Patch reward is a more precise rewarding characterization that serves as a fine- grained expertise measurement and visual explainability tool. Specifically, we present Adversarial Imitation Learning with Patch Rewards (PatchAIL), which employs a patch-based discriminator to measure the expertise of different local parts from given images and provide patch rewards. The patch-based knowledge is also used to regularize the aggregated reward and stabilize the training. We evaluate our method on DeepMind Control Suite and Atari tasks. The experiment results have demonstrated that PatchAIL outperforms baseline methods and pro- vides valuable interpretations for visual demonstrations.
@article{liu2023visual,
title={Visual imitation learning with patch rewards},
author={Liu, Minghuan and He, Tairan and Zhang, Weinan and Yan, Shuicheng and Xu, Zhongwen},
journal={arXiv preprint arXiv:2302.00965},
year={2023}
}
|
|
|
pdf |
abstract |
bibtex |
arXiv
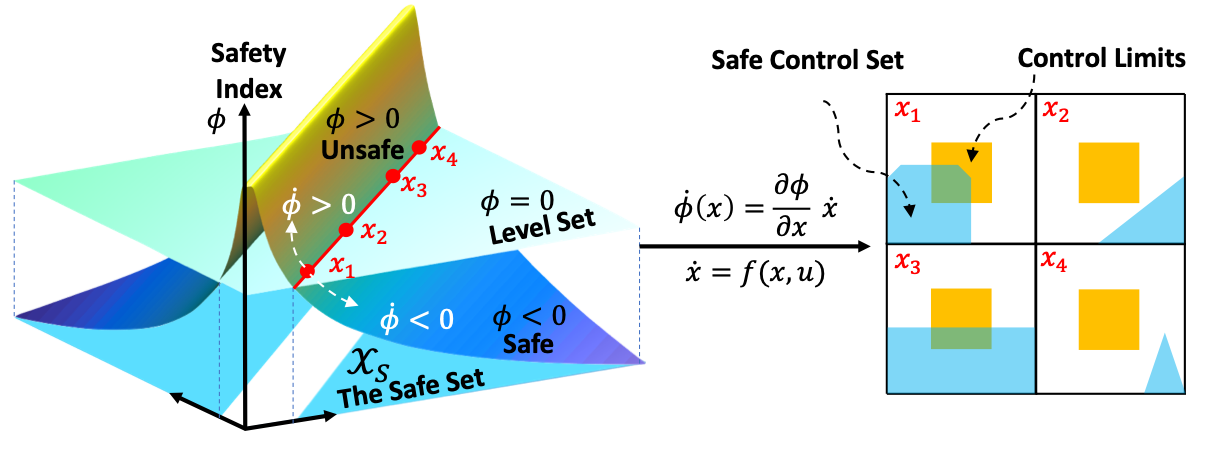
Control systems often need to satisfy strict safety requirements. Safety index provides a handy way to evaluate the safety level of the system and derive the resulting safe control policies. However, designing safety index functions under control limits is difficult and requires a great amount of expert knowledge. This paper proposes a framework for synthesizing the safety index for general control systems using sum-of-squares programming. Our approach is to show that ensuring the non-emptiness of safe control on the safe set boundary is equivalent to a local manifold positiveness problem. We then prove that this problem is equivalent to sum-of-squares programming via the Positivstellensatz of algebraic geometry. We validate the proposed method on robot arms with different degrees of freedom and ground vehicles. The results show that the synthesized safety index guarantees safety and our method is effective even in high-dimensional robot systems.
@inproceedings{zhao2023safety,
title={Safety index synthesis via sum-of-squares programming},
author={Zhao, Weiye and He, Tairan and Wei, Tianhao and Liu, Simin and Liu, Changliu},
booktitle={2023 American Control Conference (ACC)},
pages={732--737},
year={2023},
organization={IEEE}
}
|
|
pdf |
abstract |
bibtex |
arXiv
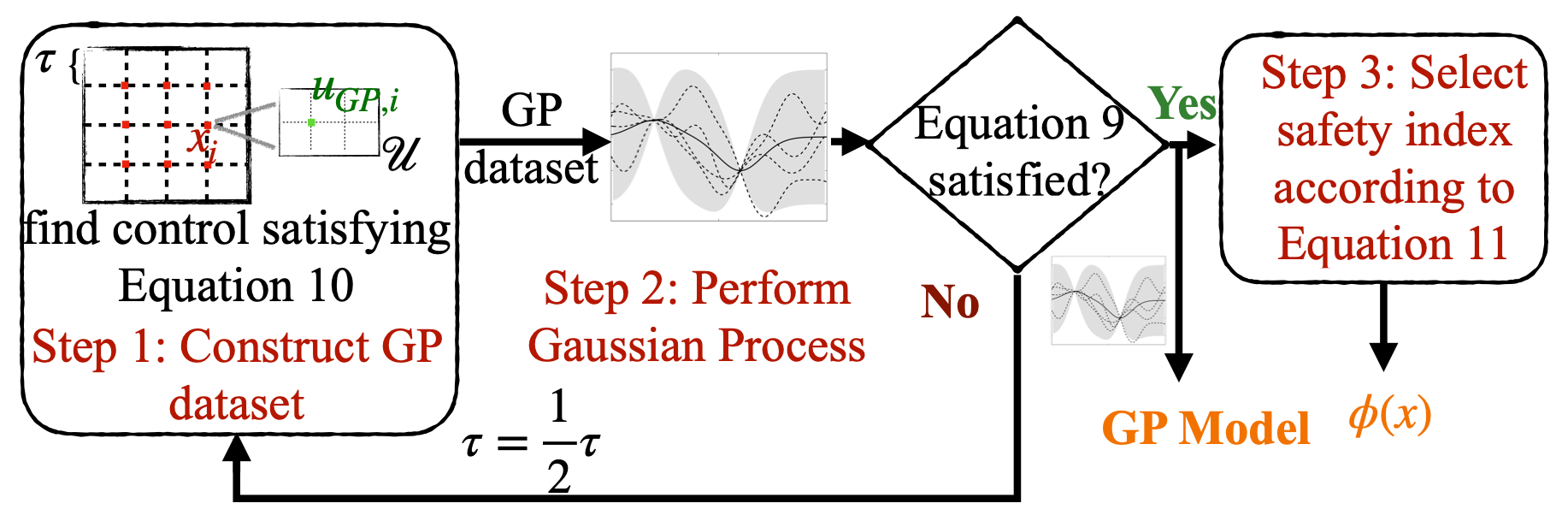
Safety is one of the biggest concerns to applying reinforcement learning (RL) to the physical world. In its core part, it is challenging to ensure RL agents persistently satisfy a hard state constraint without white-box or black-box dynamics models. This paper presents an integrated model learning and safe control framework to safeguard any agent, where its dynamics are learned as Gaussian processes. The proposed theory provides (i) a novel method to construct an offline dataset for model learning that best achieves safety requirements; (ii) a parameterization rule for safety index to ensure the existence of safe control; (iii) a safety guarantee in terms of probabilistic forward invariance when the model is learned using the aforementioned dataset. Simulation results show that our framework guarantees almost zero safety violation on various continuous control tasks.
@inproceedings{zhao2023probabilistic,
title={Probabilistic safeguard for reinforcement learning using safety index guided gaussian process models},
author={Zhao, Weiye and He, Tairan and Liu, Changliu},
booktitle={Learning for Dynamics and Control Conference},
pages={783--796},
year={2023},
organization={PMLR}
}
|
|
pdf |
abstract |
bibtex |
arXiv
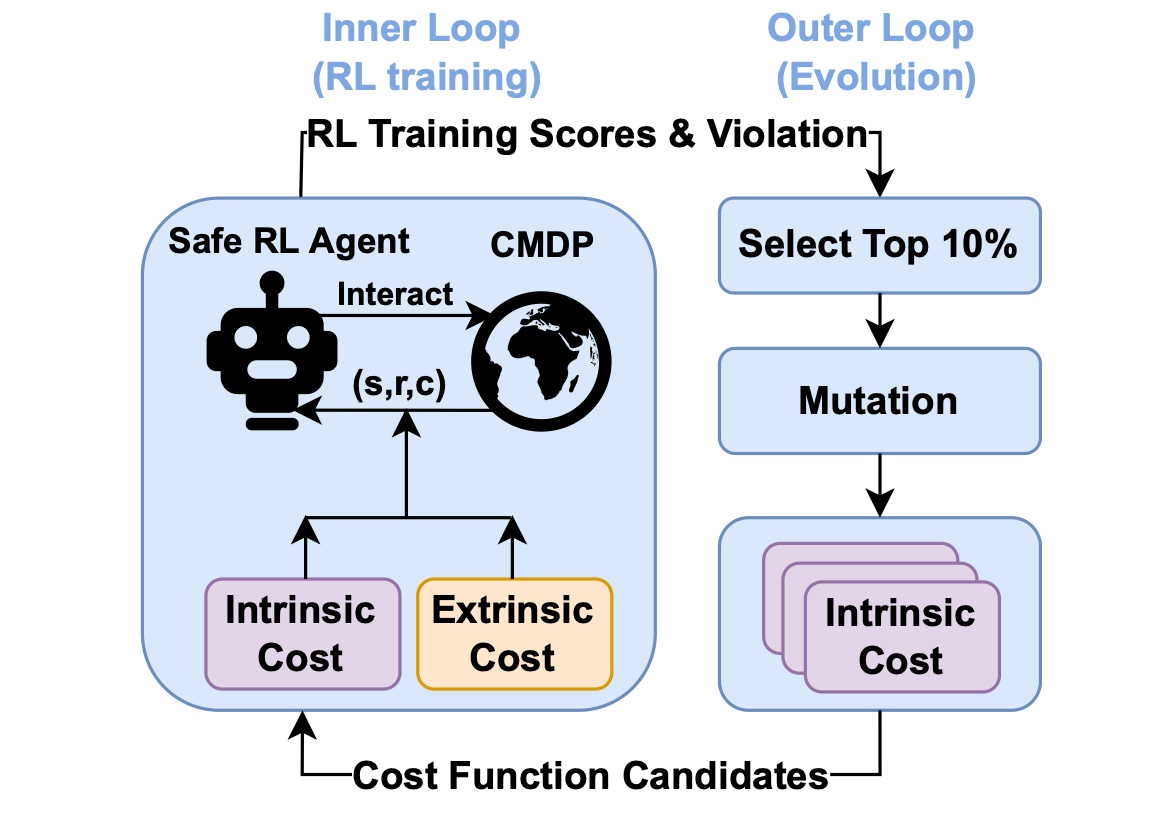
Safety is a critical hurdle that limits the application of deep reinforcement learning (RL) to real-world control tasks. To this end, constrained reinforcement learning leverages cost functions to improve safety in constrained Markov decision processes. However, such constrained RL methods fail to achieve zero violation even when the cost limit is zero. This paper analyzes the reason for such failure, which suggests that a proper cost function plays an important role in constrained RL. Inspired by the analysis, we propose AutoCost, a simple yet effective framework that automatically searches for cost functions that help constrained RL to achieve zero-violation performance. We validate the proposed method and the searched cost function on the safe RL benchmark Safety Gym. We compare the performance of augmented agents that use our cost function to provide additive intrinsic costs with baseline agents that use the same policy learners but with only extrinsic costs. Results show that the converged policies with intrinsic costs in all environments achieve zero constraint violation and comparable performance with baselines.
@article{he2023autocost,
title={Autocost: Evolving intrinsic cost for zero-violation reinforcement learning},
author={He, Tairan and Zhao, Weiye and Liu, Changliu},
journal={arXiv preprint arXiv:2301.10339},
year={2023}
}
|
|
webpage |
pdf |
abstract |
bibtex |
arXiv |
code
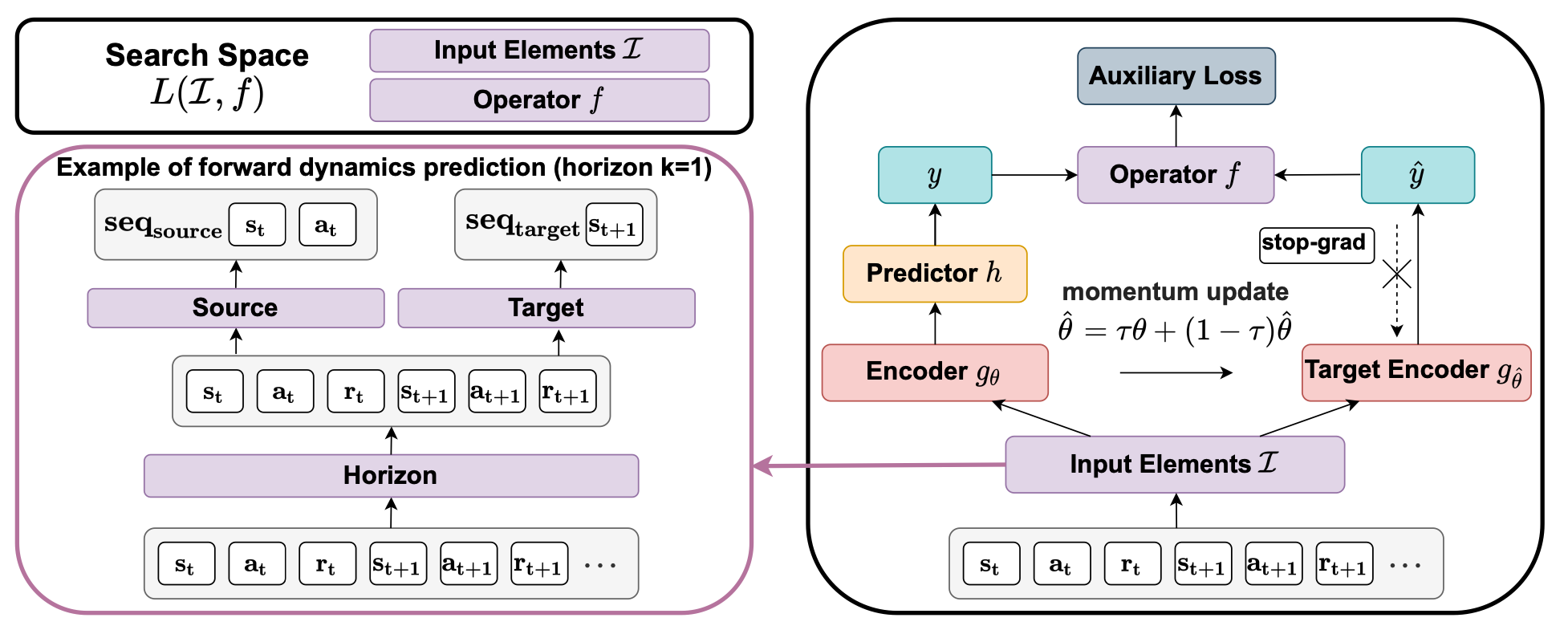
A good state representation is crucial to solving complicated reinforcement learning (RL) challenges. Many recent works focus on designing auxiliary losses for learning informative representations. Unfortunately, these handcrafted objectives rely heavily on expert knowledge and may be sub-optimal. In this paper, we propose a principled and universal method for learning better representations with auxiliary loss functions, named Automated Auxiliary Loss Search (A2LS), which automatically searches for top-performing auxiliary loss functions for RL. Specifically, based on the collected trajectory data, we define a general auxiliary loss space of size 7.5×1020 and explore the space with an efficient evolutionary search strategy. Empirical results show that the discovered auxiliary loss (namely, A2-winner) significantly improves the performance on both high-dimensional (image) and low-dimensional (vector) unseen tasks with much higher efficiency, showing promising generalization ability to different settings and even different benchmark domains. We conduct a statistical analysis to reveal the relations between patterns of auxiliary losses and RL performance.
@inproceedings{zhao2021model,
title={Model-free safe control for zero-violation reinforcement learning},
author={Zhao, Weiye and He, Tairan and Liu, Changliu},
booktitle={5th Annual Conference on Robot Learning},
year={2021}
}
|
|
pdf |
abstract |
bibtex |
openreview |
code
While deep reinforcement learning (DRL) has impressive performance in a variety of continuous control tasks, one critical hurdle that limits the application of DRL to physical world is the lack of safety guarantees. It is challenging for DRL agents to persistently satisfy a hard state constraint (known as the safety specification) during training. On the other hand, safe control methods with safety guarantees have been extensively studied. However, to synthesize safe control, these methods require explicit analytical models of the dynamic system; but these models are usually not available in DRL. This paper presents a model-free safe control strategy to synthesize safeguards for DRL agents, which will ensure zero safety violation during training. In particular, we present an implicit safe set algorithm, which synthesizes the safety index (also called the barrier certificate) and the subsequent safe control law only by querying a black-box dynamic function (e.g., a digital twin simulator). The theoretical results indicate the implicit safe set algorithm guarantees forward invariance and finite-time convergence to the safe set. We validate the proposed method on the state-of-the-art safety benchmark Safety Gym. Results show that the proposed method achieves zero safety violation and gains 95 cumulative reward compared to state-of-the-art safe DRL methods. Moreover, it can easily scale to high-dimensional systems.
@inproceedings{zhao2021model,
title={Model-free safe control for zero-violation reinforcement learning},
author={Zhao, Weiye and He, Tairan and Liu, Changliu},
booktitle={5th Annual Conference on Robot Learning},
year={2021}
}
|
|
|
pdf |
abstract |
bibtex |
arXiv |
code
A good state representation is crucial to solving complicated reinforcement learning (RL) challenges. Many recent works focus on designing auxiliary losses for learning informative representations. Unfortunately, these handcrafted objectives rely heavily on expert knowledge and may be sub-optimal. In this paper, we propose a principled and universal method for learning better representations with auxiliary loss functions, named Automated Auxiliary Loss Search (A2LS), which automatically searches for top-performing auxiliary loss functions for RL. Specifically, based on the collected trajectory data, we define a general auxiliary loss space of size 7.5×1020 and explore the space with an efficient evolutionary search strategy. Empirical results show that the discovered auxiliary loss (namely, A2-winner) significantly improves the performance on both high-dimensional (image) and low-dimensional (vector) unseen tasks with much higher efficiency, showing promising generalization ability to different settings and even different benchmark domains. We conduct a statistical analysis to reveal the relations between patterns of auxiliary losses and RL performance.
@inproceedings{zhao2021model,
title={Model-free safe control for zero-violation reinforcement learning},
author={Zhao, Weiye and He, Tairan and Liu, Changliu},
booktitle={5th Annual Conference on Robot Learning},
year={2021}
}
|

|
Android Code |
iOS Code |
Farewell Video
A carefree forum platform for SJTUers sharing and talking with anonymous identity. More than 10000+ users used「无可奉告」in the SJTU campus. |

|
I host WhynotTV Podcast / WhynotTV播客, a deep, professional, hardcore, long-form (2-4 hours) AI tech video podcast—focusing on
- in-depth discussions about AI/technology; - breaking down underlying technical details and business logic; - while also exploring life wisdom and personal growth philosophy. You can find the podcast on YouTube | Bilibili | Spotify | Apple Podcast | 小宇宙 | RSS |
|
International Conference on Robotics and Automation (ICRA) 2025
International Conference on Intelligent Robots and Systems (IROS) 2025 International Conference on Computer Vision (ICCV) 2025 IEEE Transactions on Robotics (TRO) 2025 IEEE Robotics and Automation Letters (RA-L) 2025 Robotics: Science and Systems (RSS) 2025 International Conference on Machine Learning (ICML), 2024, 2025 International Conference on Learning Representations (ICLR), 2024, 2025 IEEE Conference on Decision and Control (CDC), 2023 Conference on Neural Information Processing Systems (NeurIPS), 2023, 2024 Learning for Dynamics & Control Conference (L4DC) 2023 AAAI Conference on Artificial Intelligence (AAAI) 2023, 2024, 2025 Conference on Robot Learning (CoRL) 2022, 2023, 2024 |
|
|